Openings
We have several openings (internship & full-time). More details and application here.
Research
I am interested in computer vision, domain adaptation, image rendering, inverse problems, and photography. Much of my research is about training robust recognition systems on scarce data and bridging the gap between real and synthetic modalities.
Zhongpai GaoEC,
Benjamin PlancheEC,
Meng Zheng,
Xiao Chen,
Terrence Chen,
Ziyan Wu
Annual Conference on Neural Information Processing Systems (NeurIPS), 2024 (EC equal contribution)
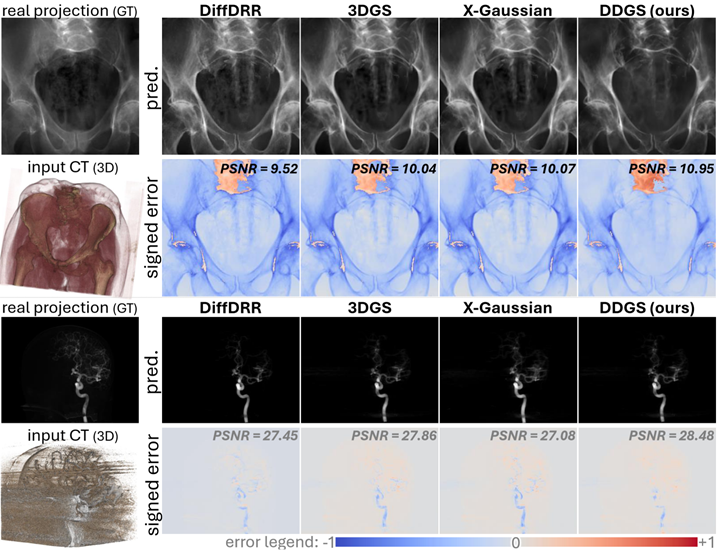
Digitally reconstructed radiographs (DRRs) are 2D X-ray images simulated from 3D CT volumes, commonly used preoperatively but limited intraoperatively due to computational challenges, especially with physics-based Monte Carlo methods. While analytical DRRs are more efficient, they miss anisotropic X-ray image formation phenomena. We introduce a novel approach combining realistic physics-based X-ray simulation with efficient, differentiable DRR generation using 3D Gaussian splatting. Our direction-disentangled 3DGS separates isotropic and direction-dependent radiosity, approximating anisotropic effects without complex runtime simulations.
Tianyu Luan,
Zhongpai Gao,
Luyuan Xie,
Abhishek Sharma,
Hao Ding,
Benjamin Planche,
Meng Zheng,
Ange Lou,
Terrence Chen,
Junsong Yuan,
Ziyan Wu
European Conference on Computer Vision (ECCV), 2024
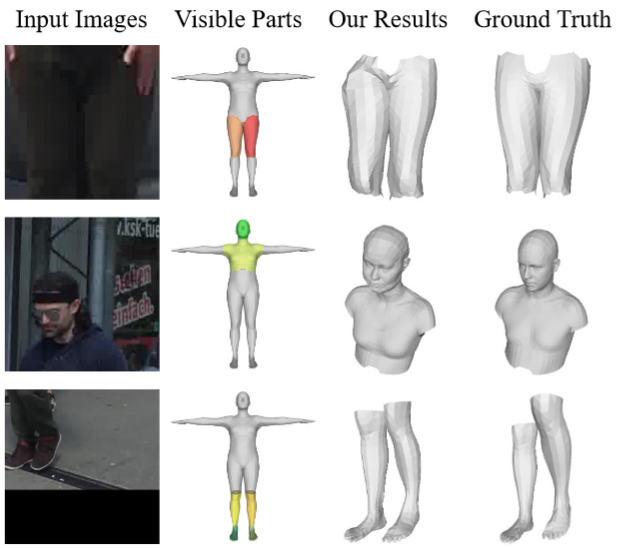
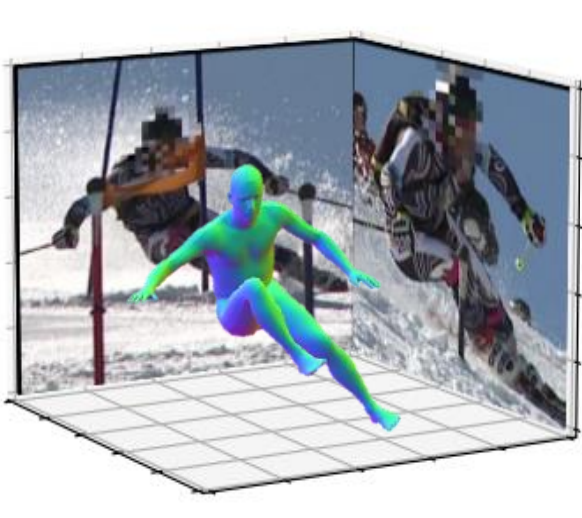
We introduce a novel bottom-up approach for human body mesh reconstruction, specifically designed to address the challenges posed by partial visibility and occlusion in input images. Our method reconstructs human body parts independently before fusing them, thereby ensuring robustness against occlusions. We design Human Part Parametric Models that independently reconstruct the mesh from a few shape and global-location parameters, without inter-part dependency. A specially designed fusion module then seamlessly integrates the reconstructed parts, even when only a few are visible.
Meng Zheng,
Benjamin Planche,
Zhongpai Gao,
Terrence Chen,
Richard J. Radke,
Ziyan Wu
Medical Image Computing and Computer Assisted Intervention (MICCAI), 2024 [early accept]
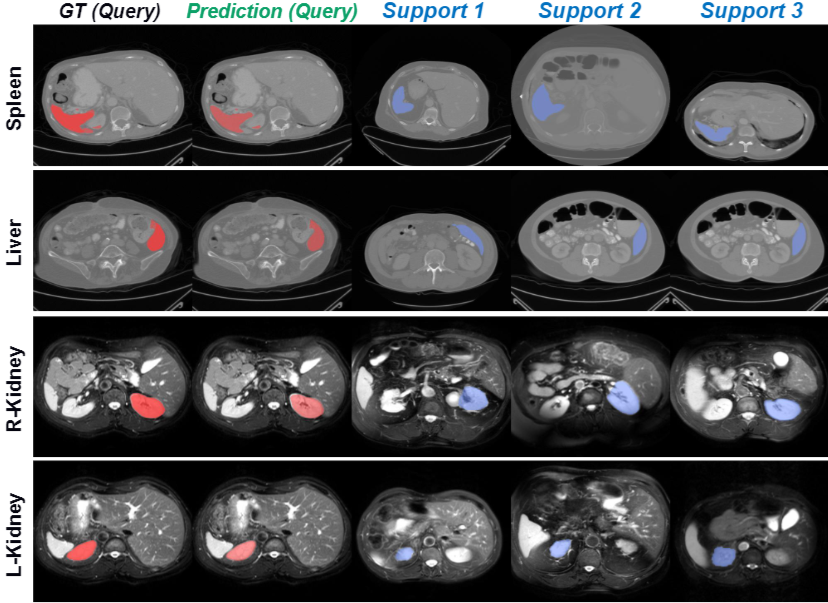
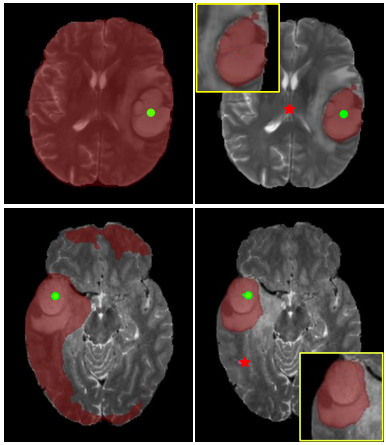
We present MSFSeg, a novel few-shot 3D segmentation framework with a lightweight multi-surrogate fusion (MSF). MSFSeg is able to automatically segment unseen 3D objects/organs (during training) provided with one or a few annotated 2D slices or 3D sequence segments, via learning dense query-support organ/lesion anatomy correlations across patient populations. Our proposed MSF module mines comprehensive and diversified morphology correlations between unlabeled and the few labeled slices/sequences through multiple designated surrogates, making it able to generate accurate cross-domain 3D segmentation masks given annotated slices or sequences.
Ange Lou,
Benjamin Planche,
Zhongpai Gao,
Yamin Li,
Tianyu Luan,
Hao Ding,
Terrence Chen,
Jack Noble
Ziyan Wu
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
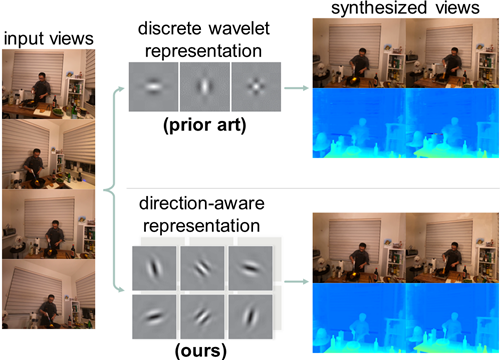
NeRF models using plane-based explicit representations struggle to achieve high-fidelity rendering for scenes with complex motions. In response we present a novel direction-aware representation (DaRe) approach, where the learned representation undergoes an inverse dual-tree complex wavelet transformation (DTCWT) to recover plane-based information. DaReNeRF computes features for each space-time point by fusing vectors from these recovered planes, yielding more accurate NVS results. Furthermore, we introduce a trainable masking approach mitigating storage issues w.r.t. DTCWT parameters, without significant performance decline.
Zhongpai Gao,
Huayi Zhou,
Meng Zheng,
Benjamin Planche,
Terrence Chen,
Ziyan Wu
International Conference on Learning Representations (ICLR), 2024
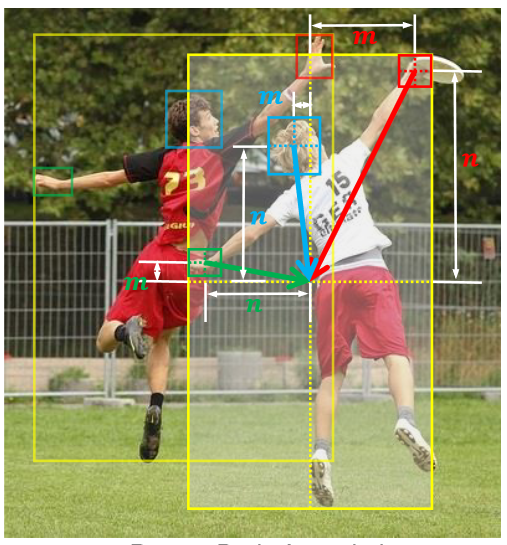
PBADet is a novel one-stage, anchor-free approach for part-body association detection. Building upon the anchor-free object representation across multi-scale feature maps, we introduce a singular part-to-body center offset that effectively encapsulates the relationship between parts and their parent bodies. Our design is inherently versatile and capable of managing multiple parts-to-body associations without compromising on detection accuracy or robustness.
Yuchun Liu,
Benjamin Planche,
Meng Zheng,
Zhongpai Gao,
Pierre Sibut-Bourde,
Fan Yang,
Terrence Chen,
M Salman Asif,
Ziyan Wu
AAAI Conference on Artificial Intelligence (AAAI), 2024
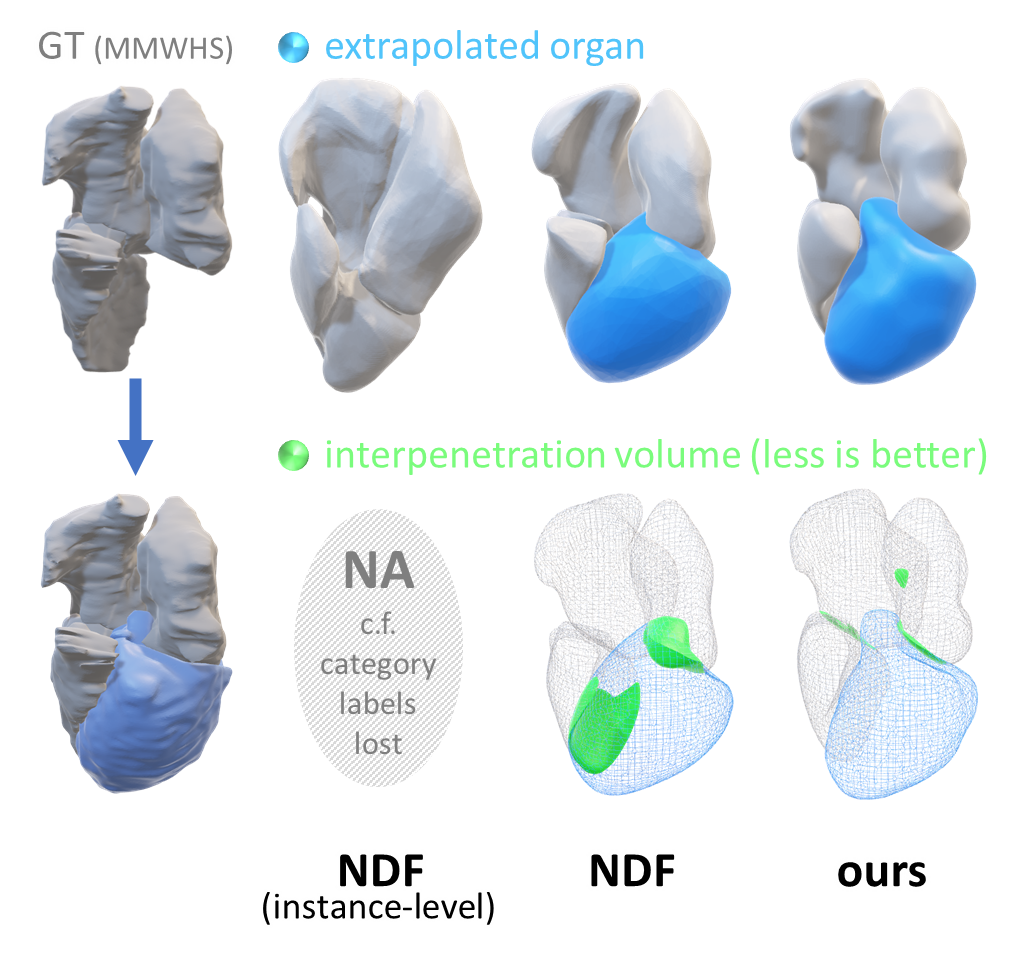
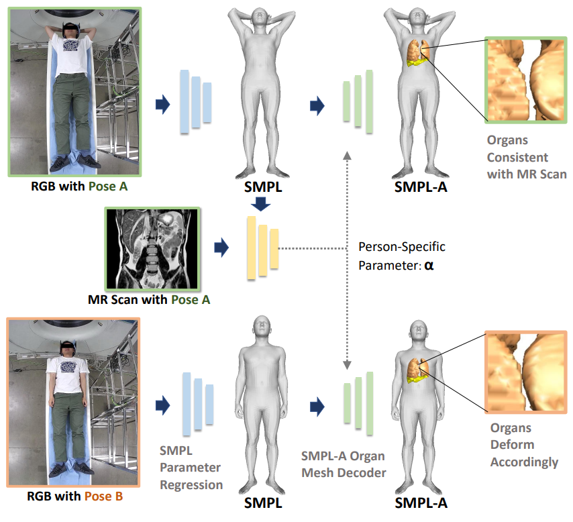
We propose MODIF, a multi-object deep implicit function that jointly learns the deformation fields and instance-specific latent codes for multiple objects at once. Our emphasis is on non-rigid, non-interpenetrating entities such as organs. To effectively capture the interrelation between these entities and ensure precise, collision-free representations, our approach facilitates signaling between category-specific fields to adequately rectify shapes. We also introduce novel inter-object supervision: an attraction-repulsion loss is formulated to refine contact regions between objects.
Zikui Cai,
Zhongpai Gao,
Benjamin Planche,
Meng Zheng,
Terrence Chen,
M Salman Asif,
Ziyan Wu
AAAI Conference on Artificial Intelligence (AAAI), 2024
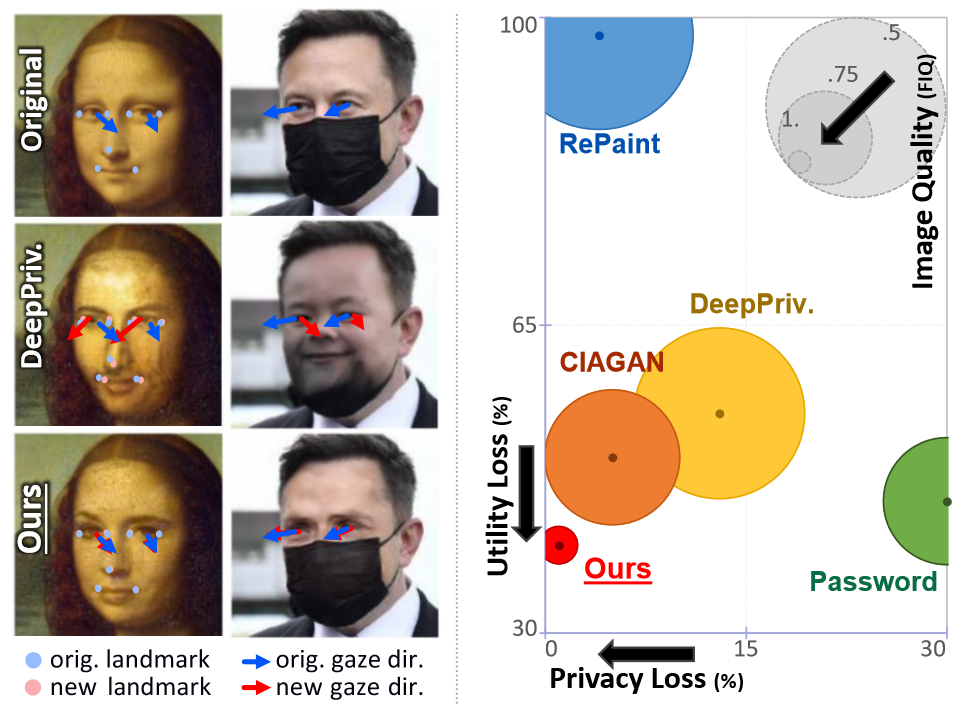
Solutions to de-identify sensitive images of individuals often compromise non-identifying facial attributes relevant to downstream tasks. We introduce Disguise, an algorithm to seamlessly de-identify facial images while ensuring the usability of the modified data. Our solution is firmly grounded in the domains of differential privacy and ensemble-learning research. It involves extracting and substituting depicted identities with synthetic ones, generated using variational mechanisms to maximize obfuscation and non-invertibility. Additionally, we leverage supervision from a mixture-of-experts to disentangle and preserve other utility attributes.
Xuan Gong,
Liangchen Song,
Meng Zheng,
Benjamin Planche,
Terrence Chen,
Junsong Yuan,
David Doermann,
Ziyan Wu
AAAI Conference on Artificial Intelligence (AAAI), 2023 [oral]
We propose a novel simulation-based training pipeline for multi-view human mesh recovery, which (a) relies on intermediate 2D representations which are more robust to synthetic-to-real domain gap; (b) leverages learnable calibration and triangulation to adapt to more diversified camera setups; and (c) progressively aggregates multi-view information in a canonical 3D space to remove ambiguities in 2D representations.
Peri Akiva,
Benjamin Planche,
Aditi Roy,
Peter Oudemans,
Kristin Dana
Computers and Electronics in Agriculture, 2022
Our goal is to develop state-of-the-art computer vision algorithms for image-based crop evaluation and weather-related risk assessment to support real-time decision-making for growers. Our cranberry bog monitoring system maps cranberry density (based on fruit instance segmentation) and predicts short-term cranberry internal temperatures (predicting solar irradiation and fruit temperature in an end-to-end differentiable network).
Xuan Gong,
Liangchen Song,
Rishi Vedula,
Abhishek Sharma,
Meng Zheng,
Benjamin Planche,
Arun Innanje,
Terrence Chen,
Junsong Yuan,
David Doermann,
Ziyan Wu
IEEE Transactions on Medical Imaging (TMI), 2022
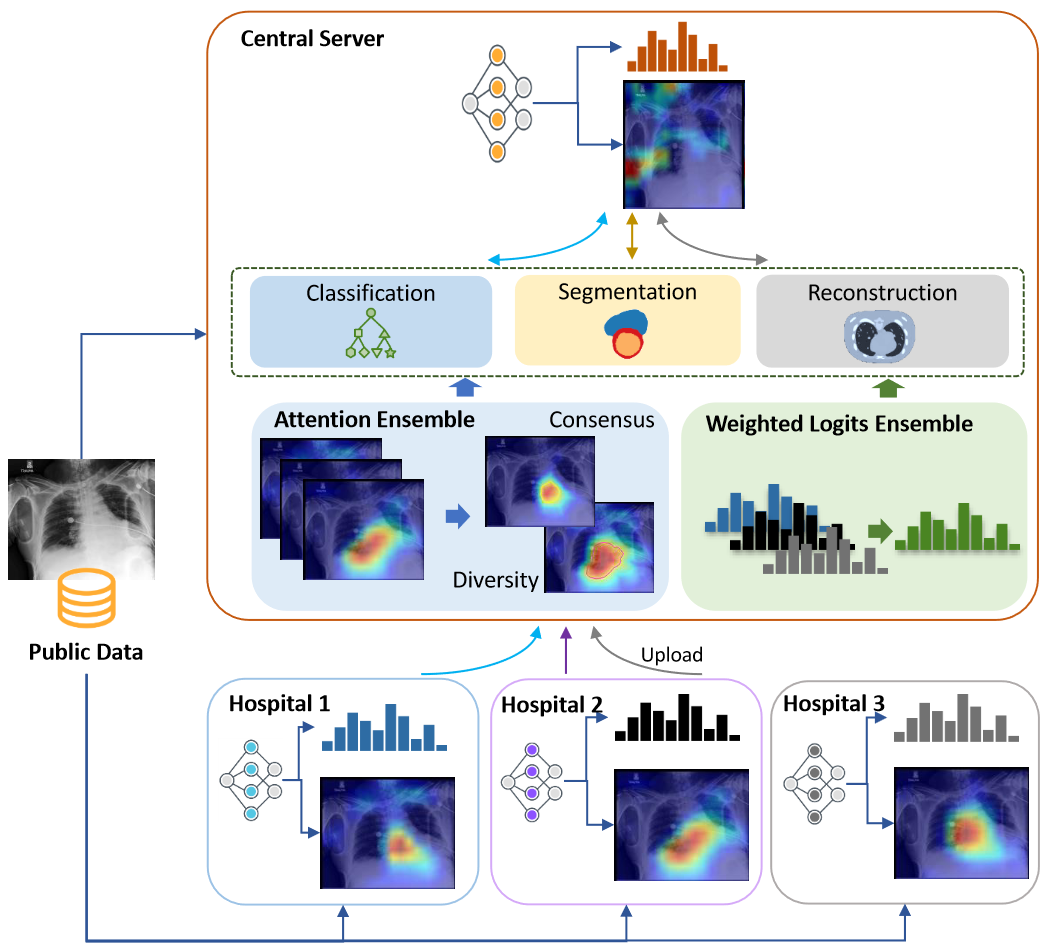
We propose a privacy-preserving FL framework leveraging unlabeled public data for one-way offline knowledge distillation. The central model is learned from local knowledge via ensemble attention distillation. Our technique uses decentralized and heterogeneous local data like existing FL approaches, but more importantly, it significantly reduces the risk of privacy leakage. We demonstrate that our method achieves very competitive performance with more robust privacy preservation based on extensive experiments on image classification, segmentation, and reconstruction tasks.
Liangchen Song,
Xuan Gong,
Benjamin Planche,
Meng Zheng,
David Doermann,
Junsong Yuan,
Terrence Chen,
Ziyan Wu
European Conference on Computer Vision (ECCV), 2022 [oral]
We leverage a neural motion field for estimating the motion of all points in a multiview setting. Modeling the motion from a dynamic scene with multiview data is challenging due to the ambiguities in points of similar color and points with time-varying color. We propose to regularize the estimated motion to be predictable. If the motion from previous frames is known, then the motion in the near future should be predictable. Therefore, we introduce a predictability regularization by first conditioning the estimated motion on latent embeddings, then by adopting a predictor network to enforce predictability on the embeddings.
[project webpage]
Xuan Gong,
Meng Zheng,
Benjamin Planche,
Srikrishna Karanam,
Terrence Chen,
David Doermann,
Ziyan Wu
European Conference on Computer Vision (ECCV), 2022
We propose cross-representation alignment utilizing the complementary information from the robust but sparse representation (2D keypoints). Specifically, the alignment errors between initial mesh estimation and both 2D representations are forwarded into regressor and dynamically corrected in the following mesh regression. This adaptive cross-representation alignment explicitly learns from the deviations and captures complementary information: robustness from sparse representation and richness from dense representation.
Qin Liu,
Meng Zheng,
Benjamin Planche,
Srikrishna Karanam,
Terrence Chen,
Marc Niethammer,
Ziyan Wu
European Conference on Computer Vision (ECCV), 2022
We ask the question: can our model directly predict where to click, so as to further reduce the user interaction cost? To this end, we propose PseudoClick, a generic framework that enables existing segmentation networks to propose candidate next clicks. These automatically generated clicks, termed pseudo clicks in this work, serve as an imitation of human clicks to refine the segmentation mask. We build PseudoClick on existing segmentation backbones and show how our click prediction mechanism leads to improved performance.
Meng Zheng,
Xuan Gong,
Benjamin Planche,
Fan Yang,
Ziyan Wu
Medical Image Computing and Computer Assisted Intervention (MICCAI), 2022 [early accept]
We propose a generic modularized 3D patient modeling method consists of (a) a multi-modal keypoint detection module with attentive fusion for 2D patient joint localization, to learn complementary cross-modality patient body information, leading to improved keypoint localization robustness and generalizability in a wide variety of imaging and clinical scenarios; and (b) a self-supervised 3D mesh regression module which does not require expensive 3D mesh parameter annotations to train, bringing immediate cost benefits for clinical deployment.
Hengtao Guo,
Benjamin Planche,
Meng Zheng,
Srikrishna Karanam,
Terrence Chen,
Ziyan Wu
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
We present the first learning-based approach to estimate the patient's internal organ deformation for arbitrary human poses in order to assist with radiotherapy and similar medical protocols. The underlying method first leverages medical scans to learn a patient-specific representation that potentially encodes the organ's shape and elastic properties. During inference, given the patient's current body pose information and the organ's representation extracted from previous medical scans, our method can estimate their current organ deformation to offer guidance to clinicians.
Benjamin Planche,
Rajat Vikram Singh
IEEE/CVF International Conference on Computer Vision (ICCV), 2021
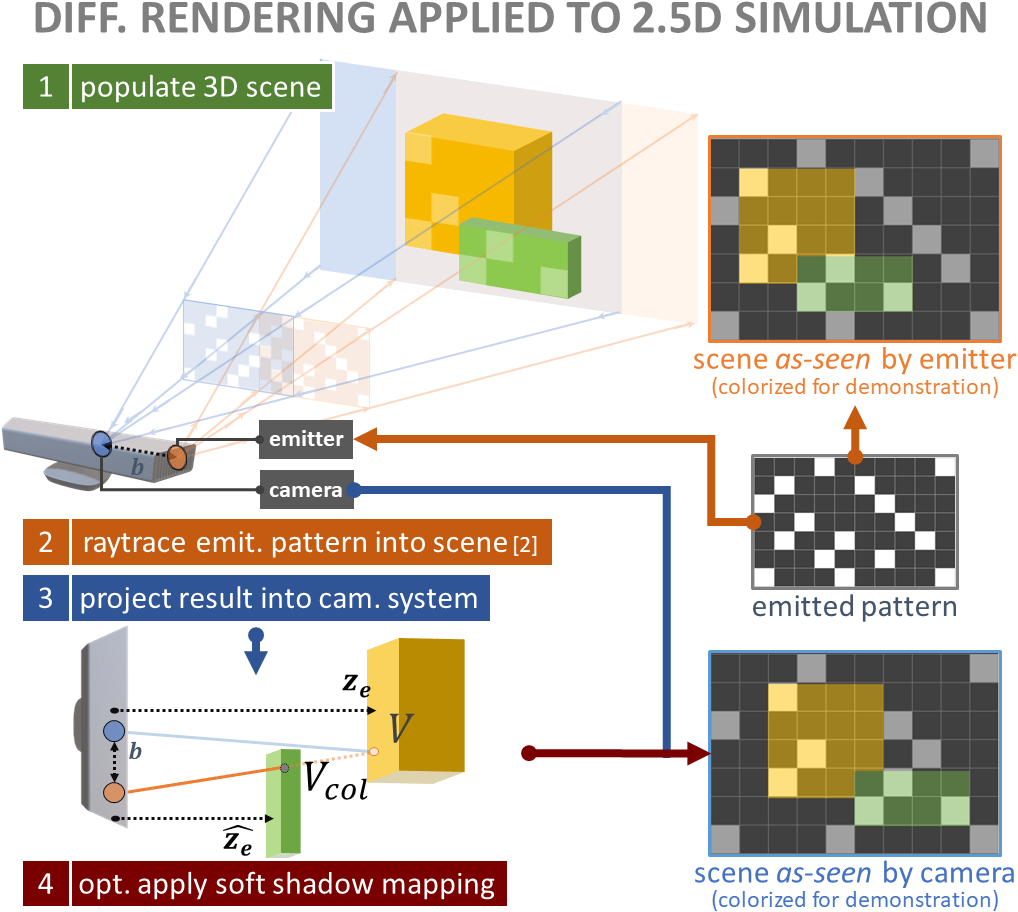
We introduce DDS, a novel end-to-end differentiable simulation pipeline for the generation of realistic depth scans, built on physics-based 3D rendering and custom block-matching algorithms. Each module can be differentiated w.r.t sensor and scene parameters; e.g., to automatically tune the simulation for new devices over some provided scans or to leverage the pipeline as a 3D-to-2.5D transformer within larger computer-vision applications.
[full version, with sup-mat]
Peri AkivaEC,
Benjamin PlancheEC,
Aditi Roy,
Kristin Dana,
Peter Oudemans,
Michael Mars
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021 (EC equal contribution)
We propose an end-to-end cranberry health monitoring system to enable and support real time cranberry over-heating assessment and facilitate informed decisions that may sustain the economic viability of farms. Our system performs: 1) cranberry fruit segmentation to delineate fruit regions that are exposed to sun, 2) prediction of cloud coverage and sun irradiance to estimate the inner temperature of exposed cranberries.
Benjamin Planche,
Xuejian Rong,
Ziyan Wu,
Srikrishna Karanam,
Harald Kosch,
YingLi Tian,
Jan Ernst,
Andreas Hutter
Annual Conference on Neural Information Processing Systems (NeurIPS), 2019
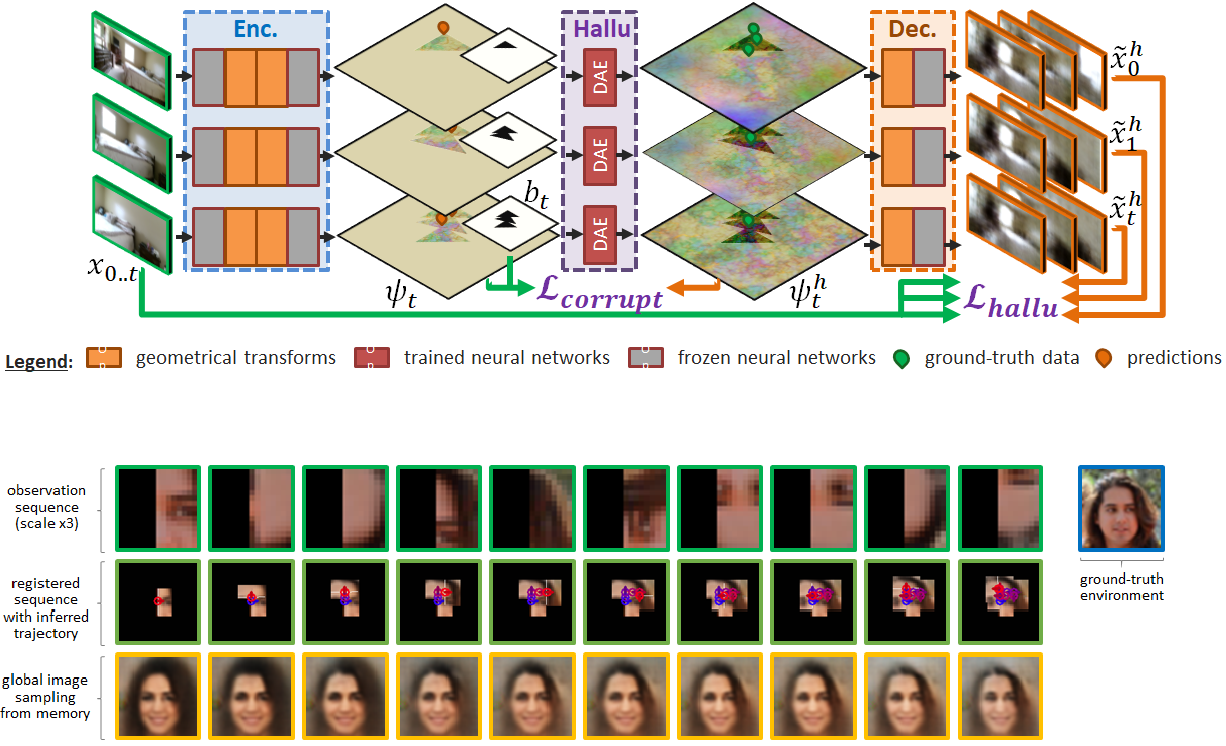
We present a method to incrementally generate complete 2D or 3D scenes. Our framework can register observations from a non-localized agent in a global representation, which can be used to synthesize new views as well as fill in gaps in the representation while observing global consistency.
Benjamin PlancheEC,
Sergey ZakharovEC,
Ziyan Wu,
Harald Kosch,
Andreas Hutter,
Slobodan Ilic
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019 (EC equal contribution)
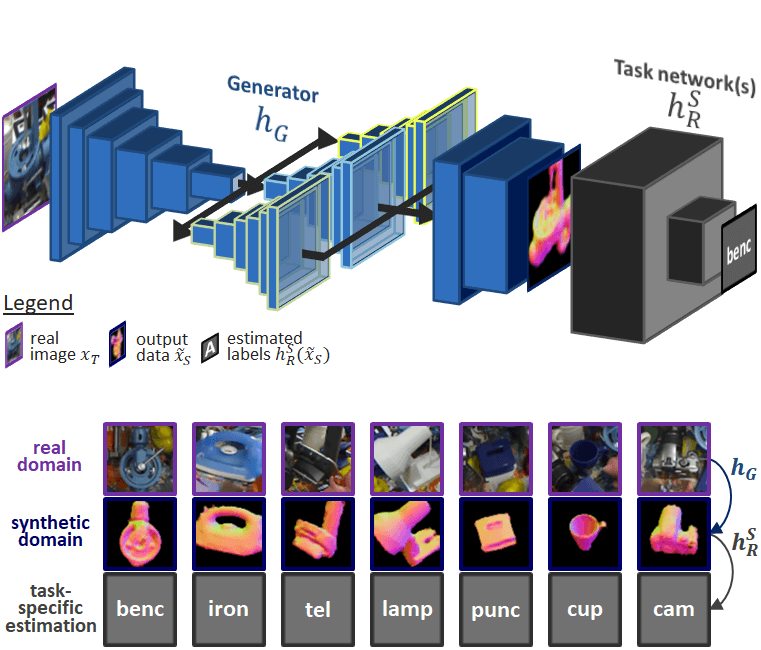
Tackling real/synthetic domain adaptation from a different angle, we introduce a pipeline to map unseen target samples into the synthetic domain used to train task-specific methods. Denoising the data and retaining only the features these recognition algorithms are familiar with, our solution greatly improves their performance.
Sergey ZakharovEC,
Benjamin PlancheEC,
Ziyan Wu,
Harald Kosch,
Andreas Hutter,
Slobodan Ilic
International Conference on 3D Vision (3DV), 2018 [oral] (EC equal contribution)
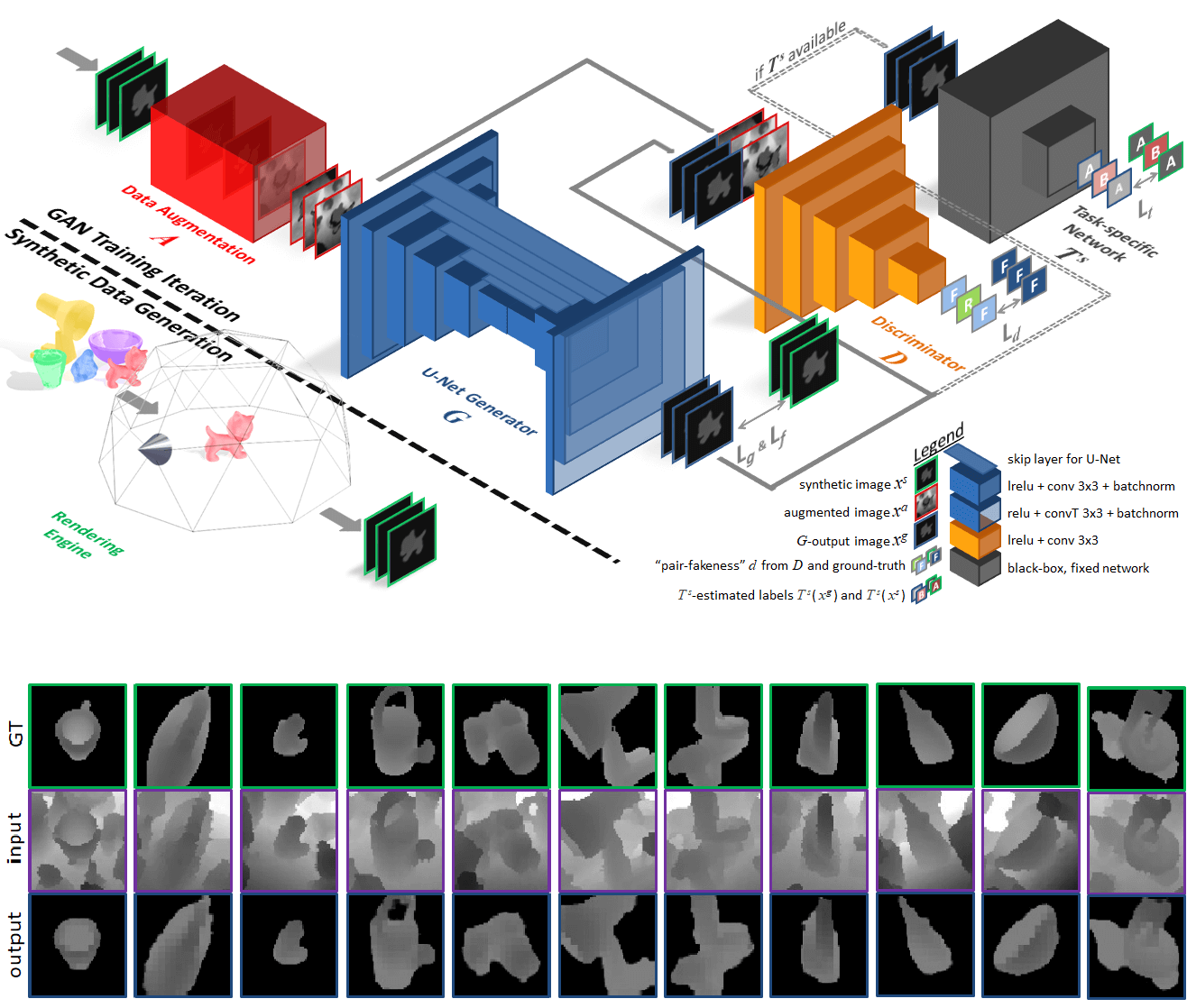
We propose a novel approach leveraging only CAD models to bridge the realism gap for depth images. Purely trained on synthetic data, playing against an extensive augmentation pipeline in an unsupervised manner, our GAN learns to effectively segment depth images and recover the clean synthetic-looking depth information even from partial occlusions.
Benjamin Planche,
Ziyan Wu,
Kai Ma,
Shanhui Sun,
Stefan Kluckner,
Oliver Lehmann,
Terrence Chen,
Andreas Hutter,
Sergey Zakharov,
Harald Kosch,
Jan Ernst
International Conference on 3D Vision (3DV), 2017 [oral]
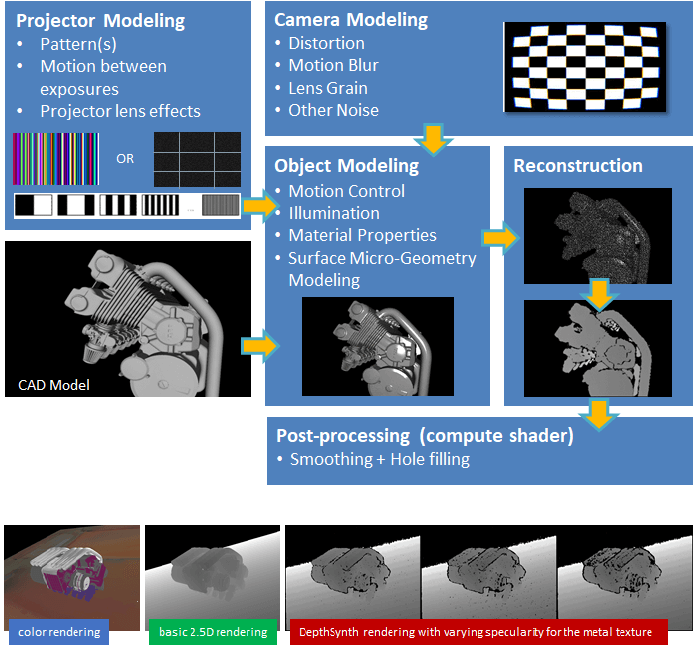
We present an end-to-end framework which simulates the whole mechanism of depth sensors, generating realistic depth data from 3D models by comprehensively modeling vital factors, e.g., sensor noise, material reflectance, surface geometry. Our solution covers a wider range of devices and achieves more realistic results than previous methods.
Sergey Zakharov,
Wadim Kehl,
Benjamin Planche,
Andreas Hutter,
Slobodan Ilic
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017
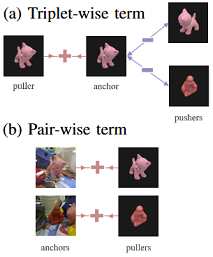
Inspired by the descriptor learning approach of Wohlhart et al. [link], we propose a method that introduces the dynamic margin in the manifold learning triplet loss function. Introducing the dynamic margin allows for faster training times and better accuracy of the resulting low dimensional manifolds.
Benjamin PlancheEC,
Bryan Isaac MalynEC,
Daniel Buldon BlancoEC,
Manuel Cerrillo BermejoEC
International Conference on Ubiquitous Computing and Ambient Intelligence (UCAmI), 2014 [oral] (EC equal contribution)
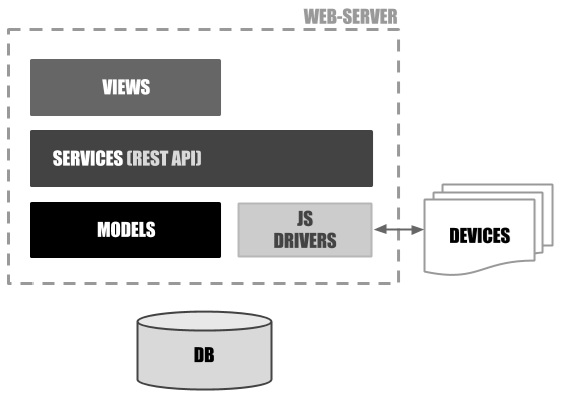
Brightnest is a generic and user-friendly web-based Home Automation System. Its interface provides users with information on the whole system or with control over the devices and their rules. The modular architecture is based on "JS Drivers", their REST API imitating the way a computer usually handles new devices.
Book
A few years ago, I got the opportunity to co-author a book, teaching how to leverage deep learning to create powerful image processing apps with TensorFlow 2.0 and Keras. While some technical examples in the book are now a bit outdated outdated (with regard to the TensorFlow API), the book also covers the foundations of deep learning, illustrated with publicly-available code examples (see GitHub link below).
Benjamin Planche and Eliot Andres
Packt Publishing, 2019
Computer vision solutions are becoming increasingly common, making their way in fields such as health, automobile, social media, and robotics. With the release of TensorFlow 2, the brand new version of Google's open source framework for machine learning, it is the perfect time to jump on board and start leveraging deep learning for your visual applications!
This book is a practical guide to building high performance systems for object detection, segmentation, video processing, smartphone applications, and more. By its end, you will have both the theoretical understanding and practical skills to solve advanced computer vision problems with TensorFlow 2.0.
[Amazon | Packt | GitHub]